Rev. Orkopata. (2024). Vol. 3, N° 4 (2024), pp. 25-48
Inferencias en memes y noticias digitales sobre política: una prueba de comprensión multimodal en estudiantes universitarios costarricenses[1]
Inferences in memes and digital news about politics: a multimodal comprehension test among costa rican university students
Inférences dans les mêmes et les actualités numériques sur la politique : un test de compréhension multimodale chez les étudiants universitaires costariciens
Wendy Chavarría Ortiz[2]
https://orcid.org/0009-0005-0201-710X
Universidad de Costa Rica, San Pedro de Montes de Oca - San José, Costa Rica
wendy.chavarria@ucr.ac.cr (correspondencia)
Adrián Vergara Heidke
https://orcid.org/0000-0001-9487-7089
Universidad de Costa Rica, San Pedro de Montes de Oca - San José, Costa Rica
adrian.vergara@ucr.ac.cr
Alejandro Cambronero
https://orcid.org/0009-0007-8781-550X
Karl-Franzens-Universität Graz, Graz - Graz, Austria
a.cambronero-delgadillo@uni-graz.at
DOI : https://doi.org/10.35622/j.ro.2024.04.002
Recibido: 18-VIII-2024 / Aceptado: 22-XI-2024 / Publicado: 28-XI-2024
Resumen: Cuando nos encontramos ante un acontecimiento político, en redes sociales se suelen generar discusiones acaloradas, las cuales se complementan con memes y noticias digitales. Lo dicho plantea la necesidad de ahondar en cómo se comprenden estos textos. Esta investigación tiene como objetivo describir las inferencias realizadas por estudiantes de Administración de la Universidad Nacional tras la exposición a dichos textos, utilizando una prueba diseñada para evaluar inferencias. Se aplicó un enfoque cualitativo, con un pilotaje inicial, una revisión de expertos y se evaluó a 40 estudiantes de primer y cuarto año mediante seis estímulos (tres memes y tres noticias digitales). Los resultados revelaron que los memes generaron más inferencias esperables (91,67 % de reconocimiento de referentes) en comparación con las noticias (63,33 %), así como una mayor identificación de relaciones lógico-semánticas en memes (82,5 %) frente a noticias (30 %). Se encontró que el enfoque en la construcción de inferencias optativas relacionadas con noticias estuvo en lo verbal (94,7 %), mientras que en los memes la mayoría se enfocó en una integración (59,10 %) seguido del modo gráfico (22,72 %). Finalmente, las intenciones más comunes fueron las propias de cada género. Se cierra con recomendaciones para futuras investigaciones sobre textos multimodales.
Palabras clave: alfabetización digital, comprensión, inferencias, multimodalidad.
Abstract: When we encounter a political event, heated discussions are often generated on social media, which are complemented by memes and digital news. This highlights the need to explore how these texts are understood. The aim of this research is to describe the inferences made by students of Business Administration at the National University after exposure to these texts, using a test designed to assess inferences. A qualitative approach was applied, with an initial pilot, expert reviews, and the evaluation of 40 first- and fourth-year students through six stimuli (three memes and three digital news articles). The results revealed that memes generated more expected inferences (91.67% recognition of referents) compared to news articles (63.33%), as well as a higher identification of logical-semantic relationships in memes (82.5%) compared to news articles (30%). It was found that the focus on building optional inferences related to news was mainly verbal (94.7%), while in memes, most of the focus was on integration (59.10%), followed by the graphic mode (22.72%). Finally, the most common intentions were those specific to each genre. The paper concludes with recommendations for future research on multimodal texts.
Keywords : comprehension, digital literacy, inferences, multimodality.
Resumo : Lorsqu’un événement politique se produit, des discussions animées ont souvent lieu sur les réseaux sociaux, complétées par des mèmes et des actualités numériques. Cela soulève la nécessité d’approfondir la manière dont ces textes sont compris. L’objectif de cette recherche est de décrire les inférences réalisées par des étudiants en Administration de l’Université Nationale après exposition à ces textes, en utilisant un test conçu pour évaluer les inférences. Une approche qualitative a été appliquée, avec un pilotage initial, une révision par des experts et l’évaluation de 40 étudiants de première et quatrième année à travers six stimuli (trois mèmes et trois actualités numériques). Les résultats ont révélé que les mèmes généraient plus d’inférences attendues (91,67 % de reconnaissance des référents) par rapport aux actualités (63,33 %), ainsi qu’une plus grande identification des relations logique-sémantiques dans les mèmes (82,5 %) par rapport aux actualités (30 %). Il a été constaté que l’accent mis sur la construction d’inférences optionnelles liées aux actualités était principalement verbal (94,7 %), tandis que dans les mèmes, la majorité de l’accent était mis sur l’intégration (59,10 %), suivie du mode graphique (22,72 %). Enfin, les intentions les plus courantes étaient celles propres à chaque genre. L’étude se conclut par des recommandations pour de futures recherches sur les textes multimodaux.
Palavras chave : compréhension, inférences, littératie numérique, multimodalité.
INTRODUCCIÓN
Las discusiones públicas sobre política se han vuelto cada vez más comunes con la incorporación de las redes sociales en la vida de las personas, en especial con la divulgación de textos multimodales como memes y noticias digitales (Siles, 2020). En este contexto, entender cómo se comprenden los textos que circulan en la web se vuelve imprescindible. A raíz de lo anterior, en esta investigación se describen las inferencias producidas por un grupo de estudiantes de primero y cuarto año de la carrera de Administración de la Universidad Nacional a partir de la exposición a memes y noticias digitales sobre política nacional. Para ello, se construyó una prueba que permitió evaluar las inferencias producidas luego de la exposición a memes y noticias digitales sobre política nacional.
Previamente, se ha observado que los memes políticos cumplen funciones sociales como la crítica social (Chavarría et al., en prensa; Ramírez & Siles, 2020) y tienden a servir como herramientas para comunicar, debatir o compartir ideas de forma eficaz. Las noticias digitales sobre política igualmente cuentan con una función social, ya que estas ponen sobre la mesa información de posible interés público y sirven como herramienta para incentivar una opinión sobre determinado acontecimiento (Califano, 2015; Oliva, 2014). Además, al responder a las necesidades de su contexto, han recibido modificaciones al pasar a la virtualidad y se ha registrado la interacción en Facebook con ambos textos a partir del seguimiento oculomotor en los estudios de Vergara et al. (2020a, 2020b). Lo anterior brinda claridad en cuanto a que son textos con los que nos relacionamos como sociedad. Por su parte, aunque el análisis de los memes y las noticias digitales resulta fundamental, esta investigación se enfoca en la comprensión de estos textos multimodales, específicamente en el nivel inferencial, puesto que muchos autores comparten la idea de que es esencial para la comprensión (Van Dijk & Kintsch, 1983).
Actualmente, se encuentran una vasta cantidad de estudios interesados en los memes de internet, sin embargo, hasta el momento, solo el estudio de Yus (2019) ahonda en el proceso de comprensión de memes. Por su parte, en relación con los trabajos sobre noticias digitales, la mayoría (Vraga et al., 2016; Sülflow et al., 2018) se enfocó en percepción y consumo de noticias en redes sociales.
Por su parte, Parodi et al. (2020a) plantean la escasez de investigaciones donde se estudie el proceso inferencial en la construcción de la representación mental multimodal. En este documento se aporta en esta línea una prueba/test sobre el proceso inferencial específicamente en memes y noticias digitales, mediante la integración de la información proveniente de modos distintos, así como del conocimiento previo.
Además, se presentan los resultados del segundo pilotaje de la aplicación de esta prueba a un grupo de estudiantes universitarios de primero y último año de la carrera de Administración de empresas de la Universidad Nacional de Costa Rica. Lo anterior permite comparar si el proceso universitario mejoró o no la capacidad para producir más inferencias y/o elaborar respuestas más esperables. Es decir, las personas participantes deben inferir la información implícita del texto con ayuda de su conocimiento previo e integrar con los datos gráficos y verbales presentes en cada texto, todo ello en la memoria de trabajo (Mayer, 2005).
MARCO TEÓRICO
La multimodalidad es un enfoque teórico-metodológico dentro de la lingüística que aborda, por un lado, los textos como productos elaborados a partir de múltiples modos o recursos semióticos y, por otro, la comprensión de dichos textos multimodales (Kress & Van Leeuwen, 2001, p.12). En cuanto a la comprensión multimodal, se vuelve necesario rescatar brevemente la teoría del código dual de Sadoski y Paivio (2013), la teoría del aprendizaje multimedia de Mayer (2005) y la teoría de la comunicabilidad de Parodi (2011). Dichas fuentes se complementan para tener una visión integral del proceso de comprensión.
La teoría del código dual estipula que el procesamiento se da en dos códigos mentales, los logogens procesan el lenguaje verbal y forman representaciones verbales mentales y las imagens procesan elementos gráficos y elaboran imágenes mentales. Adicionalmente, Mayer (2005, p.41) plantea que la integración de la información nueva con la conocida se da en la memoria de trabajo, independientemente del modo semiótico en el que se presenten los estímulos. De la mano con lo anterior, Parodi (2011, p.93) propone que todo lector debe ser capaz de dar cuenta de lo comprendido y no solo puede, sino que tiene la necesidad y lo hace para sí o para otros. A este proceso se le llama principio de acreditabilidad de lo comprendido.
Ahora bien, un proceso central para la comprensión, el cual es rescatado por todos los autores antes mencionados, es el inferencial. Al respecto, Parodi (2014, p.58) define las inferencias desde dos puntos de vista: como proceso mental y como producto. En cuanto al primero, apunta que las inferencias son aquellas operaciones mentales que nos permiten acceder a un nuevo conocimiento a partir de lo no explícito al acercarse a un texto. Por otro lado, se entiende como producto cuando es el resultado que se obtiene tras el proceso de comprensión.
En concreto, la clasificación de inferencias de Parodi (2005) distingue entre fundamentales y optativas. Las fundamentales ayudan a la creación de una representación mental coherente de la información textual, otros autores las llaman 'relacionadoras' o `puente' y permiten realizar una comprensión en el nivel superficial o base. Las optativas, también conocidas como ‘elaborativas’, ‘valorativas’ y ‘proyectivas,’ son aquellas que el lector construye utilizando más el conocimiento previo que activó a partir del texto leído que la información explícita del texto. Estas permiten al lector cuestionar, integrar/contrastar con conocimiento de otras fuentes, valorar la veracidad, pertinencia y validez, así como realizar cálculos a futuro sobre lo mencionado en el texto leído.
MÉTODO
La presente investigación es de tipo cualitativo, en la cual se elaboró una prueba de comprensión de textos multimodales (memes y noticias digitales sobre política nacional). Se aplicó el primer pilotaje en septiembre del 2023 en seis estudiantes universitarios en la Universidad Nacional, Heredia, Costa Rica, tres de primer año y tres de cuarto año, sin especificidad de carrera. Luego de ello, se realizaron algunos cambios para mejorar la prueba y fue sometida a la evaluación de cinco expertos. Posteriormente, se aplicó el segundo pilotaje entre el 04 de febrero y el 22 de abril, este específicamente en estudiantes universitarios de la carrera de Administración de empresas de la Universidad Nacional de Costa Rica. La selección de la muestra de estudiantes para la prueba aplicada no se basó en un criterio sistemático, sino por la disponibilidad de las personas participantes, facilitada por la colaboración de los docentes.
La segunda aplicación consistió en mostrar seis estímulos (tres memes y tres noticias digitales sobre política nacional) con límite de tiempo. Participaron veinte estudiantes de primer año de carrera y veinte de cuarto año de carrera, divididos, a su vez, por cuotas de género, como se ilustra en la Tabla 1.
Tabla 1
Distribución de las personas participantes por género y nivel de carrera
|
Participantes |
G1 |
G2 |
Total |
|
M |
10 |
10 |
20 |
|
H |
10 |
10 |
20 |
|
Total |
20 |
20 |
40 |
Nota. Las personas participantes del G1 cursan primer año de la carrera de administración de la UNA y los del G2 cuarto año de la misma carrera.
Diseño del instrumento y pasos para aplicación
Estímulos
En cuanto a los estímulos, estos se tratan de textos que circulaban en la web, se eligieron por presentar la estructura más frecuente[3] en un corpus de cien memes y cien noticias digitales sobre política. Con respecto a las fuentes de ese corpus mencionado, se tomaron de páginas de memes sobre política nacional y páginas web de periódicos digitales como CRHoy.[4]
En la Figura 1 se presenta el meme uno, el referente se encuentra presente en la imagen modificadora, se trata de la cara del expresidente de Costa Rica, Carlos Alvarado Quesada y como intención se presenta una crítica sobre la gestión del mismo.
Figura 1
Meme uno

En el caso de la Figura 2, el referente es el Partido Liberación Nacional, al cual se hace alusión mediante el color de las letras y la bandera colocada en la imagen modificadora, su intención es criticar el uso de las personas en condición de pobreza durante la campaña electoral.
Figura 2
Meme dos

Con respecto a la Figura 3, el referente se encuentra en el modo verbal, se trata del presidente actual de Costa Rica, Rodrigo Chaves Robles. En cuanto a intención, consiste en cuestionar el apoyo al presidente en redes sociales, en medio de un contexto donde varias investigaciones demuestran pago a granjas de troles y apoyo de cuentas vietnamitas a publicaciones del partido oficialista.
Figura 3
Meme tres

En cuanto a la noticia digital uno (ver Figura 4), el referente era la exdiputada Silvia Hernández, presente en una imagen base[5], la relación lógico semántica se encontraba entre el titular y el párrafo posterior a la fotografía.
En cuanto al referente de la noticia dos[6], este se encontraba en el título y en la imagen base, era Johnny Araya, exalcalde de San José (ver Figura 5) y la relación lógico-semántica era entre titular e imagen.
Figura 4
Noticia uno

Figura 5
Noticia dos

Finalmente, el referente de la noticia tres[7] era el edificio del Tribunal Supremo de Elecciones, en adelante TSE, el cual se presentó en la imagen base y la relación era entre la imagen y el titular (ver Figura 6).
Figura 6
Noticia tres

Evaluación de la comprensión
Para ahondar en los criterios utilizados para evaluar la comprensión, se retoma el postulado de Parodi (2005), quien plantea que la información necesaria para entender un texto se divide en dos grandes dimensiones, la literal y la inferencial. La literal abarca, principalmente, información explícita. Por su parte, la inferencial acoge la información implícita, lo no dicho. Para solicitar información de este nivel, se deben realizar preguntas que induzcan al lector a integrar y complementar lo dicho con sus saberes previos. Con base en lo anterior, el análisis se centra en la dimensión inferencial.
Ahora bien, para la creación de las preguntas se retoman claves teóricas sobre el procesamiento de textos multimodales. Una de ellas es la teoría del aprendizaje multimedia de Mayer (2005), la cual plantea que en la memoria de trabajo se une la información de distintos modos, así como con el conocimiento previo para producir un nuevo conocimiento. A su vez, como lo plantean Parodi y Julio (2017) con el principio de acreditabilidad de lo comprendido, todo lector que haya comprendido debe/puede dar cuenta de lo aprendido.
Con base en lo anterior, se plantea una pregunta que busque el reconocimiento de referentes, otra de las relaciones lógico-semánticas entre modos semióticos, otra donde deben explicar (en el caso de las noticias) o poner título (en el caso de los memes); una donde se consulta la intención del texto y, por último, una de aplicación (ver Tabla 2).
Tabla 2
Tipo y cantidad de preguntas por tipo de inferencia
|
Tipo de inferencia |
Tipo de pregunta y cantidad |
|
Fundamental |
Reconocimiento del referente. (1) |
|
Reconocimiento de relaciones lógico-semánticas. (1) |
|
|
Optativa |
Idea general/título (1) |
|
Intención (1) |
|
|
Aplicación (1) |
Como parte de las decisiones que se tomaron para describir los resultados, se cuantificaron sólo las inferencias presentes en las primeras cuatro preguntas de cada estímulo, lo cual implicó dejar por fuera las respuestas a la pregunta cinco sobre aplicación/opinión. Esto se contempló debido a que las respuestas no pudieron ser sistematizadas adecuadamente, dado que su amplitud y flexibilidad intrínsecas dificultan la categorización y el análisis estructurado. Además, como se trataba de una opinión o aplicación futura todas las respuestas debieron considerarse esperables lo cual alteraba los datos totales.
En la Tabla 3 se muestran los tipos de pregunta y la cantidad que se utilizaron para cada estímulo. Cabe aclarar que las únicas preguntas que se realizaron diferente por género textual fueron la de idea general (solo aplica para noticias) y la de título (solo para memes), con el fin de evitar que la prueba se volviera muy repetitiva y predecible.
Tabla 3
Distribución de preguntas por estímulo
|
Tipo de preguntas |
Meme 1 |
Noticia 1 |
Meme 2 |
Noticia 2 |
Meme 3 |
Noticia 3 |
|
Referente |
1 |
1 |
1 |
1 |
1 |
1 |
|
Relación lógico-semántica |
1 |
1 |
1 |
1 |
1 |
1 |
|
Idea global |
0 |
1 |
0 |
1 |
0 |
1 |
|
Título |
1 |
0 |
1 |
0 |
1 |
0 |
|
Intención |
1 |
1 |
1 |
1 |
1 |
1 |
|
Aplicación |
1 |
1 |
1 |
1 |
1 |
1 |
|
Total |
5 |
5 |
5 |
5 |
5 |
5 |
Pasos para la aplicación
Previo a la aplicación, se realizó una distribución aleatoria de los estímulos en la prueba, presentando a cada participante tres memes y tres noticias digitales en un orden intercalado y diferente, para garantizar que la evaluación fuera imparcial y sin sesgos de presentación.
Ahora bien, se aplicó la prueba en una única sesión por persona en la Facultad de Ciencias Sociales. Antes de iniciar se leyó el consentimiento y las instrucciones. Luego, se mostró el primer estímulo y se realizaron las preguntas correspondientes, el proceso se repitió con los seis estímulos.
La duración de la prueba fue de aproximadamente veinte minutos, cada vez que se mostraba un estímulo se colocaba un temporizador con el tiempo determinado para su observación. En relación con el tiempo de exposición, a diferencia del estudio de Vergara et al. (2020a), donde se les pidió a las personas participantes que observan el contenido usual de Facebook para analizar su movimiento ocular y dio como resultado que la mayoría de las personas participantes prestaron menos de cinco segundos de atención en ambos géneros, en este trabajo se les pidió que leyeran los textos (memes y noticias) con el objetivo de responder unas preguntas posteriores. Es por ello, que se consideró necesario acrecentar el tiempo de exposición. Dicho aumento tomó en cuenta la cantidad de contenido verbal de cada género textual, por lo que se consideró que las noticias necesitaban 20s mientras los memes solamente 10s.
Categorías y su aplicación
Las categorías se definieron de dos maneras, las asociadas con inferencias fundamentales se determinaron previo a la aplicación, debido a que estas inferencias se encuentran muy cercanas al estímulo que se presenta, mientras que las utilizadas para inferencias optativas se crearon de forma inductiva porque, al basarse en el conocimiento previo de cada participante, se definieron hasta tener las respuestas y encontrar los patrones y peculiaridades de las mismas. Estas últimas serían categorías emergentes.
Se plantearon las categorías esperable y no esperable para dividir el total de las respuestas. Se considera esperable si la inferencia coincide con la información del texto, con el contexto sociopolítico al que se hace referencia y si consigue elaborar una representación mental coherente del texto. Por su lado, se marca como no esperable cuando la inferencia se sale del texto, del contexto referido y/o cuando no es coherente.
Luego de filtrar las respuestas esperables, se trabajó el reconocimiento de referentes en inferencias fundamentales, el cual suele ser buscado comúnmente en las pruebas de comprensión, solo que estas suelen enfocarse en el modo verbal, como en el caso de Parodi (2005). En textos multimodales, el referente se puede presentar en varios modos semióticos.
En segundo lugar, se da la identificación de relaciones lógico-semánticas principalmente en inferencias fundamentales. Las categorías de relaciones lógico-semánticas de Daly y Unsworth (2011) se suelen utilizar más en el análisis de textos multimodales e incorporarlas en una prueba de comprensión resulta innovador. Esta inclusión se dio debido a que los estímulos son textos multimodales y la identificación de las conexiones entre los modos suele ser necesaria para comprender el texto.
Ambas identificaciones se dieron entre las respuestas a las preguntas 1 y 2. En la Tabla 4, se sistematizan los referentes y las relaciones lógico-semánticas sobre las que se preguntó. Cabe resaltar que directamente no se esperaba que las personas participantes respondieron con la categoría teórica, sino que reconocieran la relación en uso y realizarán la integración de los modos. Asimismo, los resultados a estas preguntas se cruzaron con respecto al nivel educativo.
Tabla 4
Referentes y relaciones lógico-semánticas por estímulo
|
Estímulos |
Referente |
Relación lógico-semántica |
|
Meme 1 |
Carlos Alvarado (gráfico) |
Causa: entre imagen y palabras. |
|
Meme 2 |
Mono, partidos políticos, PLN (gráfico) |
Proyección: entre palabras e imagen base. |
|
Meme 3 |
Chaves, presidente de Costa Rica (verbal) |
Ejemplo: entre imagen y palabras. |
|
Noticia 1 |
Silvia Hernández, diputada (gráfico) |
Causa: entre título y cuerpo de la noticia. |
|
Noticia 2 |
Johnny Araya, exalcalde de San José (ambos) |
Exposición: entre imagen y título. |
|
Noticia 3 |
Edificio del Tribunal Supremo de Elecciones (gráfico) |
Exposición: entre imagen y título. |
Nota. Se aceptaron respuestas relacionadas con el referente, por ejemplo, alguien pudo responder “Carlos Alvarado” o “expresidente de Costa Rica” y ambas se contemplaron como esperables.
Por su parte, con respecto a las categorías para la sistematización de las respuestas de la pregunta 3[8], se verificó, inicialmente, el tipo de inferencia (fundamental u optativa) y, en caso de que fuesen optativas, se consideró si la respuesta se construyó con énfasis en los elementos gráficos, verbales, a la integración de ambos modos o indeterminado si resultó imposible identificar el origen de la inferencia.
Finalmente, las respuestas sobre la pregunta 4[9] trataban sobre posibles intenciones del texto. Al respecto, se crearon dos categorías, la primera intención asociadas al género, como, en el caso de los memes, informar (Siles, 2020), criticar (Rowan, 2015, p. 52) y hacer reír (Meso et al., 2017, p.673), y con otras no prototípicas del género, las cuales se identificaron como categorías emergentes. Un ejemplo de ellas sería la burla, la cual se diferencia de la intención hacer reír, debido a que la burla implica dejar en mal a alguien. En el caso de las noticias, las intenciones asociadas al género son informar (Rost, 2009) y captar atención (Rost, 2009).
Para concluir, es fundamental destacar que las respuestas consideradas en este análisis son aquellas que han sido filtradas como esperables. Asimismo, se centró la atención únicamente en las respuestas específicas a las preguntas formuladas, omitiendo deliberadamente los comentarios en los que las personas participantes se desviaban del tema.
RESULTADOS
En relación con el tipo de inferencias esperables de las primeras cuatro preguntas, se encontró un total de doscientos diecinueve inferencias optativas en memes y ciento noventa y dos en noticias. Por su parte, las inferencias fundamentales fueron ciento noventa y dos en memes y ciento veinticuatro en noticias, como se observa en la Figura 7.
Figura 7[10]
Inferencias esperables totales por género textual
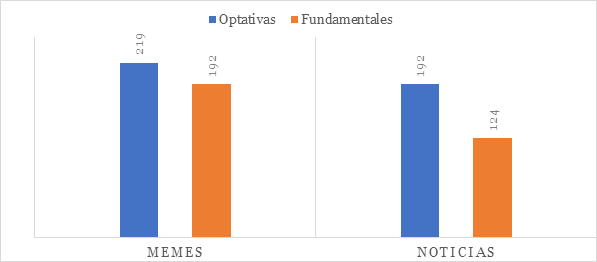
Nota. Este gráfico presenta las inferencias esperables optativas y fundamentales en los géneros textuales estudiados.
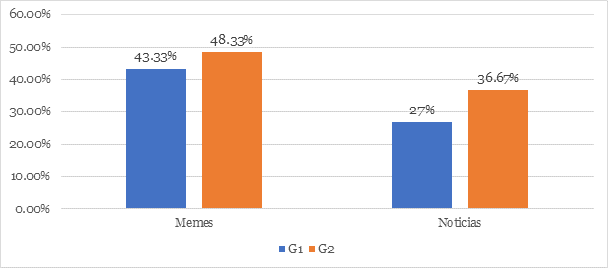
En cuanto a los referentes, de un total de ciento veinte respuestas (ver Figura 8), las personas participantes los lograron reconocer (esperables) en ciento diez ocasiones (91,67 %) al enfrentarse a los memes. Por su parte, en noticias, solo lo consiguieron setenta y seis veces (63,33 %).
Figura 8
Reconocimiento del referente por grupo
Con respecto al reconocimiento de la relación lógico-semántica, de ciento veinte respuestas, las personas participantes identificaron (esperables) noventa y nueve (82,5 %) en memes, mientras que en noticias solo lo consiguieron en treinta y seis ocasiones (30 %), como se muestra en la Tabla 5.
Tabla 5
Reconocimiento de las relaciones lógico-semánticas
|
Género textual |
G1 |
G2 |
Total |
|
Noticias |
17 (14,17 %) |
19 (15,83 %) |
36 (30 %) |
|
Memes |
48 (40 %) |
51 (42,5 %) |
99 (82,5 %) |
Por otro lado, en cuanto a la pregunta donde se les pedía título o idea general del texto, se revisó el enfoque de las respuestas optativas esperables y se encontró que para la formulación de ideas generales en noticias se basaron principalmente en el modo verbal (94,70 %), el resto (5,30 %) fueron indeterminados. En cambio, en el caso de los memes, principalmente, se marcaron los títulos con la categoría integración (59,10 %); en segundo lugar, el modo gráfico (22,72 %) y, por último, el verbal (9,09 %) y el indeterminado (9,09 %) en igual número (ver Figura 9).
Figura 9
Enfoque de las respuestas optativas sobre idea general y título

Con respecto a la pregunta sobre intención, se encontró que, de ciento veinte respuestas, en noventa y nueve (82,5 %) se asociaron con intenciones prototípicas de noticias (ver Tabla 6), mientras que en memes se asociaron con género textual en sesenta y cuatro ocasiones.
Tabla 6
Intenciones en memes y noticias digitales
|
Género textual |
Intención prototípica |
Otro |
NR |
NA |
Total |
|
Memes |
64 (53,3 %) |
39 (32,5 %) |
16 (13,3 %) |
1 (0,83 %) |
120 (100 %) |
|
Noticias |
99 (82,5 %) |
15 (12,5 %) |
5 (4,2 %) |
1 (0,83 %) |
120 (100 %) |
Nota. NR se utilizó cuando no respondieron una intención y NA cuando se dio un error en la grabación.
Por su lado, en noticias, quince (12,5 %) fueron intenciones distintas como conocer la opinión, atacar, desmeritar, dejar en mal, echar cizaña, desprestigiar, juzgar, entre otros similares, cinco (4,2 %) no respondieron ninguna intención y uno (0,83 %) no se registró bien. En cambio, en memes, sesenta y cuatro (53,33 %) fueron prototípicas de memes políticos, es decir, informar, criticar o hacer reír; mientras tanto, treinta y nueve (32,5 %) respondieron a intenciones no registradas, la más frecuente fue la burla, además, dieciséis (13,3 %) no dieron una intención e igual que en noticias en un caso (0,83 %) falló el registro. Por su parte, sobre las intenciones asociadas al género, tanto en memes como en noticias se dio más mención en los estudiantes de cuarto año que en los de primer año, como se observa en la Tabla 7.
Tabla 7
Intención genérica dividida por nivel educativo
|
Género textual |
G1 |
G2 |
Total |
|
Memes |
26 (40,6 %) |
38 (59,4 %) |
64 (100 %) |
|
Noticias |
47 (47,5 %) |
52 (52,5 %) |
99 (100 %) |
Nota. Los resultados son inferencias optativas con intenciones prototípicas divididas por nivel educativo.
DISCUSIÓN
Con respecto al total de las respuestas, se observó que los memes propiciaron mayor cantidad de inferencias esperables que las noticias. Esta particularidad se dio porque en las respuestas a noticias no esperables, en su mayoría, indicaron no recordar la información que acababan de leer. Es decir, se encontró que los memes se retienen en la memoria en mayor cantidad que las noticias. Al respecto, Cisneros et al. (2010) indican que “La diferencia en los rendimientos lectores puede residir, entonces, en el entrenamiento para el uso autorregulado y consciente de estrategias inferenciales pertinentes en cada situación de lectura” (p. 20), lo cual implica que la mejora en la construcción de inferencias en el género meme podría sugerir una mayor facilidad en el manejo estrategias de lectura enfocadas en el nivel inferencial a partir de la socialización y el conocimiento del género textual que el adiestramiento en estas mismas al acercarse al género periodístico. Aunque coincidimos con esa posibilidad, el hecho de que las personas participantes que no lograban responder a las preguntas sobre noticias comunicaran que no recordaban nada de lo que acaban de leer parece implicar que no lograron realizar una comprensión ni siquiera en el nivel literal del texto y mucho menos integrar la información con su conocimiento previo para realizar una representación mental coherente del texto, ya que no pudieron dar cuenta de lo leído (Parodi, 2011).
Por otra parte, en relación con el reconocimiento de los referentes, en noticias, principalmente, no se consiguió que mencionan el referente (51,67 %) porque gran parte de las personas participantes afirmaron que no pusieron atención a las fotografías y en otros casos porque lo desconocían, un ejemplo muy representativo es el de (i). De hecho, la noticia a la que se enfrentó esta participante fue en la que aparecía el nombre en el titular y la cara del referente en la fotografía, por lo que fue el que atinaron con más precisión. En cambio, quienes fallaron en la identificación de referentes en memes (8,33 %) lo hicieron solo por falta de conocimiento previo, no por falta de atención a la imagen. Esta particularidad resulta especialmente interesante puesto que en el consumo incidental de memes y noticias digitales que presentan Vergara et al. (2020a) el tiempo de atención mayormente fue de menos de 5 segundos para ambos géneros y la instrucción fue solo utilizar la red social Facebook con naturalidad, mientras que en este caso contaban con un objetivo de lectura, es decir, debían leer/prestar atención al texto con la instrucción de responder preguntas y, pese a ello, más del cincuenta por ciento de los participantes afirmaron no prestar atención a la imagen y no dar cuenta del referente para el caso de las noticias. Asimismo, esa atención predominante del modo verbal. Parodi (2011) la llama principio logocentrista, el cual parece indicar que las personas participantes pueden considerar que las imágenes resultan fundamentales para comprender el meme, pero en el caso de las noticias las podrían considerar accesorias. Lo anterior, además, se complementa con el ‘efecto de relevancia’ de Kaakiner y Hiona (2010), el cual implica que “los lectores son sensibles a la relevancia de la información textual para el objetivo, durante el procesamiento inicial” (Parodi et al., 2020b, p. 430). Por tanto, pareciera que las personas participantes se inclinan por el contenido verbal en las noticias porque consideran que es contenido relevante y omiten su atención a las imágenes por considerar que son irrelevantes ante la tarea de lectura impuesta.
i. “No sé, no le puse atención a la fotografía” N2-10-M-G2[11]
ii. “Doña Silvia, ella actualmente es presidenta de la CEPAL en Chile” N1-4-H-G2
iii. “Creo que era el tribunal, o algo así” N3-9-H-G2
En los casos anteriores, se observan algunas respuestas con plena claridad del referente, como en (ii). Al respecto, este participante fue el único que reconoció en ese nivel de especificación a la diputada. Otros como en (iii) no utilizaron tanto el conocimiento previo, sino que pudieron inferir el referente de la imagen por el contenido verbal.
De manera similar, las relaciones lógico-semánticas, las cuales suelen indicar la cohesión de los componentes o recursos semióticos del texto, fueron solo identificadas en treinta y seis ocasiones (30%) a causa de la falta de atención a las imágenes de las noticias. Lo anterior podría estar asociado con el hecho de que, durante la investigación de Vergara et al. (2020b, p.16), las personas participantes no realizaron movimientos integratorios entre la imagen y el contenido verbal cuando se enfrentaron a noticias digitales. De nuevo, podría implicar que las personas participantes no consideran las imágenes en este género como un elemento que aporte en gran medida al significado global del texto.
En contraparte, las personas participantes ubicaron con mayor facilidad las relaciones lógico-semánticas de los memes (82,5 %), como se observa en (iv), donde el participante explica la conexión entre la frase y la fotografía de manera clara. En (v) la participante además de responder qué se trata de un político quien realiza la pregunta inicial, agrega la asociación entre los colores verde y blanco de las letras con la bandera del Partido Liberación Nacional a partir de su conocimiento previo.
iv. “Pues porque, digamos, el meme como tal decía que los errores te hacen más fuerte, es como una forma de decir, digamos, que la persona se equivoca constantemente y que por esa razón debe ser como míster músculo, por ejemplo” M1-7-H-G2
v. “Yo lo interpreto como un político y por los colores de la letra de liberación nacional” M2-10-M-G1
Cabe resaltar que, al tratarse de un pilotaje, existen posibles mejoras en torno a las preguntas, por ejemplo, en una de las noticias no se logró que hablarán sobre la relación lógico-semántica, sino que las respuestas se enfocaron nuevamente sobre el referente, lo cual afectó los resultados.
Por otro lado, en relación con la pregunta sobre título aplicada solo a memes, se dieron resultados bastante variados, quienes sí realizaron la tarea unieron elementos de ambos modos semióticos, por lo que se marcó la fuente del título como integración en los casos (vii), ya que tomaron la estrategia de campaña del componente verbal y el referente de Liberación Nacional de la bandera y los colores de la letra. En segundo lugar, se enfocaron en el modo gráfico, como en (vi). Por otro lado, hubo quienes consideraron extraño ponerle título a un meme, ya que este género no suele contar con este componente prototípicamente, como en los casos de (viii) y (ix). Otros decían que le dejarían el título que ya traía refiriéndose a la frase inicial, estos se marcaron como no esperables. Ahora, con respecto a la pregunta sobre título, se utilizó porque se consideró que era una forma de pedirles que integrarán y explicaran en pocas palabras el meme, sin embargo, como ya se mencionó, se podría cambiar para que no genere el choque con el género textual que se produjo durante este pilotaje. Incluso, se podría sustituir por la siguiente: ¿podría describir el meme?
vi. “Carlos Fitnes” M1-5-H-G2
vii. “La estrategia de siempre de Liberación Nacional” M2 -2-M-G2
viii. “No, no sé. No me da la creatividad” M1-10-M-G2
ix. “No sé, la verdad es que está bien raro ponerle título a los memes” M2-3-H-G2
Finalmente, con respecto a la pregunta en la que se les solicitó explicar en una idea general la noticia, resultó sólo en cuatro ocasiones (5,30 %) indeterminada la fuente de la respuesta, la gran mayoría se enfocó en explicar la noticia a partir del modo verbal (94,70 %), lo cual demuestra que en ese género sigue predominando este modo y el principio logocentrista mencionado previamente.
En esta pregunta, en cuarenta y cuatro ocasiones (36,7 %) no lograron responder debido a que no recordaban lo que acababan de leer, como en (x) y (xii). A partir de ello, vale la pena recordar que el proceso de integración implica la creación de una representación mental coherente de lo leído más la combinación con el conocimiento previo (Parodi et al. 2020a, p. 790). Por tanto, al no dar cuenta de lo leído, se podría inferir que no lograron crear una representación mental coherente del texto. En cambio, otro participante, el único que recordaba sobre la situación referida, realizó la respuesta en (xi).
En relación con estos resultados, cabe resaltar que la categoría de integración resultó clave en la clasificación de estas respuestas, puesto que “cada sistema semiótico utilizado en la creación de un texto aporta una parte del significado” (Lemke, 1998 en Gómez, 2019, p.98) y, por tanto, para comprender un texto a plenitud se esperaría que se realicen las conexiones entre los modos que lo componen.
x. “No recuerdo lo que decía ya” N1-1-M-G2
xi. “Un mega caso de corrupción que relaciona a las principales alcaldías de Costa Rica con el delito de malversación de fondos no prevaricato de parte de los funcionarios públicos ya que supuestamente favorecieron a grandes constructoras a nivel nacional dándoles contratos por más del dinero que necesitaba el proyecto y sin supervisión de parte de ARESEP sobre la calidad de la construcción y uso de materiales en obra pública municipal” (N2-4-H-G2)
xii. “Sí, que se piden cambios para no me acuerdo” (N3-1-M-G2)
Con respecto a la pregunta de intención, las respuestas se dividieron en dos, si se trataron de intenciones prototípicas del género o no, como se mostró en el apartado de resultados. Las respuestas en noticias se centraron en la intención prototípica de informar como en los casos (xvii), (xviii). También algunos mencionaron más de una intención, por ejemplo (xvi) donde menciona una intención del género como informar y una no prototípica como sembrar cizaña. En memes, aunque la mayoría hizo referencia a una intención genérica como en (xiii) y (xiv), más de treinta interpretaron la burla y otras intenciones no propias del género como posibles, como en (xv). Los memes han tenido su éxito en la recepción cultural debido a que, dentro de sus intenciones comunes están el debate de ideas, mostrar el malestar de los usuarios respecto a determinado acontecimiento (criticar/cuestionar) y expresan la opinión pública desde abajo, como lo plantean Wilson y Oliveira (2022).
xiii. “Di hacer reír, supongo. Demostrar nada” (M1-3-H-G2)
xiv. “Como mostrar una triste realidad, como crítica social” (M2-4-M-G2)
xv. “De nuevo, hacer mofa de una situación que supuestamente ocurrió, aunque la verdad fue muy evidente que en publicaciones de Doña Pilar Cisneros aparecieron personas de Vietnam apoyando a Doña Pilar cuando la barrera idiomática es absolutamente muy dispareja” (M3-4-H-G2)
xvi. “Pienso que es una manera de informar al pueblo, pero también lo hacen con ese tono amarillista para que quede como esa cizaña en contra del gobierno” (N1-7-H-G1)
xvii. “Que la gente se entere de todas las cosas que están haciendo por debajo de la mesa los alcaldes” (N2-8-M-G1)
xviii. “La intención de la noticia siento que es informar a la población de la corrupción que obviamente siempre existe en los partidos políticos y que se den cuenta que esos partidos deben ser investigados. Y en cierto punto no se les debe de dar tanta confianza ya que están siendo analizados por cosas que no son correctas” (N3-6-H-G2)
Por otro lado, la elaboración de las respuestas varió incluso dentro de los grupos etarios, por ejemplo, en (xiii) y (xv), pese a ambos ser del G2, el primero se mantiene en una lectura bastante literal, mientras el segundo realiza una lectura más crítica e, incluso, con base en su conocimiento previo, retoma un ejemplo de la manipulación mediática del gobierno actual.
Pese a que las noticias digitales y los memes sobre política parecen solo compartir la intención de informar en algunos casos, su relación es estrecha en la realidad material de los usuarios de redes sociales, es común que los memes al hacer referencia a un acontecimiento político local citen una noticia o que una noticia refiera las expresiones culturales de un acontecimiento presente en un meme. En relación con lo anterior, Leane (2018) plantea que los memes suelen alimentar la agenda mediática y permiten la expresión y propagación de información.
A modo de cierre, se discutieron los principales resultados en relación con estudios previos asociados con el procesamiento y la comprensión de textos, como el principio logocentrista (2011) y el principio de acreditabilidad de lo comprendido de Parodi (2017), el efecto de relevancia de Kaakinen y Hyönä (2010), los objetivos de lectura, entre otros.
Propuesta metodológica
A continuación, se plantea la aplicación futura de esta prueba con textos multimodales y la presentación de resultados.
Propuesta metodológica para aplicación de la prueba
- Plantear un objetivo de investigación psicolingüística
- Escoger los estímulos (textos multimodales: memes, cortometrajes, noticias, mupis, publicidad, etc.)
- Analizar los componentes textuales según las capas Bateman (2008), relaciones lógico-semánticas de Daly y Unsworth (2011), categorías de imágenes de Vergara (2021), en el caso de tratarse de memes sobre política las categorías sobre estructuras y temáticas de Chavarría et al. (en prensa)[12].
- Plantear las preguntas para la prueba de acuerdo con la taxonomía de inferencias que mejor aporte a sus objetivos y el diseño (oral/escrito, abierto/cerrado, etc.).
En la Tabla 8 se muestran ejemplos de cómo aplicar los tipos de preguntas que se utilizaron para esta investigación.
Tabla 8
Tipos de pregunta y ejemplos de aplicación
|
Tipo de preguntas |
Ejemplos de aplicación |
|
Referente |
¿Quién es [determinada persona o personaje que aparece en modo verbal o gráfico]? ¿dónde suceden los acontecimientos? ¿cuándo ocurrió? |
|
Relación lógico-semántica |
Depende de la relación lógico semántica Ante una relación de proyección, por ejemplo, ¿quién dice/escribe/piensa [determinada proposición]? |
|
Idea general |
¿Cuál cree que es la idea general del texto? ¿podría explicar el texto en una idea general? ¿podría explicar el texto en sus palabras? ¿Qué cree que significa el texto? |
|
Intención |
¿Cuál cree que es la intención del texto? ¿Qué intención cree que tiene el texto? ¿Para qué cree que se creó este texto? |
- Validar la prueba mediante una evaluación de la misma por parte de cinco expertos, realizar un pilotaje en población similar a la meta y modificar de acuerdo con ambos resultados.
- Aplicar en un espacio oportuno.
Propuesta para la presentación de resultados
Utilizar las categorías correspondientes para sus objetivos. En este caso, las categorías esperables/no esperable respondieron a tres condiciones: que la respuesta fuese coherente, que se asocia al texto y al contexto al que hacía referencia el texto. Bajo esas premisas se filtraron inicialmente todas las respuestas. Luego, en la Tabla 9, se presentan las categorías de análisis correspondientes para cada tipo de pregunta realizada.
Tabla 9
Categorías en relación con el tipo de preguntas
|
Tipo de preguntas |
Categoría |
Subcategoría |
|
1. Referente |
Reconocimiento |
Sí |
|
No |
||
|
2. Relación lógico-semántica |
Reconocimiento |
Sí |
|
No |
||
|
3. Idea general/Título |
Enfoque |
Modo verbal |
|
Modo gráfico |
||
|
Integración |
||
|
Indeterminado |
||
|
4. Intención |
Prototípica del género |
Prototípica del género |
|
No prototípica |
Para futuras investigaciones, se recomienda trabajar la influencia del conocimiento del género meme en la construcción de una representación mental coherente del texto a partir de la comparación entre dos grupos generaciones/etarios muy diferenciados, por ejemplo, presentarle un grupo de memes a adultos mayores y a jóvenes.
Otra recomendación sería comparar la comprensión de un grupo de sujetos de acuerdo con los objetivos de lectura, siguiendo la línea de autores como Kaakiner y Hiona (2010) y Parodi et al. (2020b).
CONCLUSIÓN
Estos resultados permiten, en primer lugar, validar la prueba y realizar las últimas mejoras para futuras aplicaciones en textos multimodales, pues se trataba del segundo pilotaje de la misma. Una de las mejoras que se proponen es cambiar la pregunta en la que se les solicitaba crearle un título a los memes por la pregunta ¿qué cree que significa el meme? En segundo lugar, plantean la relevancia de adaptar las pruebas de comprensión a textos multimodales y a la integración de todos los componentes textuales y modos semióticos, ya no enfocados solo en el modo verbal. A nivel educativo, además, resulta valioso notar que el grado académico sí genera mejoras en la construcción de inferencias, aunque también dichas mejoras pueden estar asociadas con el conocimiento previo de la temática y del género textual.
Una de las limitaciones que se presentó fue el acceso a los participantes, ya que se debió asistir en múltiples ocasiones para completar las cuotas. También la carencia de un espacio oportuno para las grabaciones, debido a que la prueba se grabó en un lugar de descanso de la Facultad de Ciencias Sociales. Este no contaba con las condiciones de aislamiento pertinentes por lo que se volvió complicado transcribir algunos de los audios y pudo ocasionar distracciones para los participantes.
Conflicto de intereses / Competing interests:
Los autores declaran que no incurre en conflictos de intereses.
Rol de los autores /Authors Roles:
Wendy Chavarría Ortiz: Conceptualización, curación de datos, análisis formal, investigación, metodología, administración de proyectos, redacción de borrador inicial, edición y revisión.
Adrián Vergara Heidke: Supervisión, validación y visualización, edición y revisión.
Alejandro Cambronero: Validación y visualización.
Fuentes de financiamiento / Funding:
Los autores declaran no haber recibido un fondo específico para esta investigación.
Aspectos éticos / legales; Ethics / legals:
Los autores declaran no haber incurrido en aspectos antiéticos, ni haber omitido aspectos legales en la realización de la investigación.
REFERENCIAS
Bateman, J. (2008). Multimodalidad y Género. Una base para el análisis sistemático de documentos multimodales. Palgrave Macmillan.
Califano, B. (2015). Los medios de comunicación, las noticias y su influencia sobre el sistema político. Revista Mexicana de Opinión Pública, (19), 61–78. https://doi.org/10.1016/j.rmop.2015.02.001
Chavarría, W., Vergara, V., Cambronero, A. (En prensa). Memes y noticias digitales sobre política: análisis multimodal. Letras.
Cisneros, M., Olave, G., Rojas, I. (2010). La inferencia en la comprensión lectora: De la teoría a la práctica en la Educación Superior. Universidad Tecnológica de Pereira.
Daly, A., Unsworth, L. (2011). Analysis and comprehension of multimodal texts. Australian Journal of Language and Literacy, 34(1), 61–80. http://dx.doi.org/10.1007/BF03651846
Gómez, I. (2019). El meme como recurso multimodal en el proceso educativo. En N. Rey y M. Marmolejo (coords.). Viralizar la Educación. Red de experiencias didácticas en torno al Meme de Internet. Editorial Pontificia Universidad Católica de Ecuador sede Esmeraldas.
Kaakinen, J. K., Hyönä, J. (2010). Task effects on eye movements during reading. Journal of Experimental Psychology: Learning, Memory, and Cognition, 36(6), 1561-1566. https://doi.org/10.1037/a0020693
Kress, G., Van Leeuwen, T. (2001). Multimodal Discourse. The modes and media of contemporary communication. Hodder Education
Laene, D. (2018). O implícito como argumentação nos memes. Signo y Seña, 34, 79-92. https://doi.org/10.34096/sys.n34.5511
Mayer, R. (2005). Cognitive theory of multimedia learning. En R. Mayer (Ed.). The Cambridge Handbook of Multimedia Learning (pp. 31-48). Cambridge University Press.
Meso-Ayerdi, K., Mendiguren-Galdospín, T., Pérez-Dasilva, J. (2017). Memes políticos difundidos por usuarios de Twitter. Análisis de la jornada electoral del 26J de 2016. El profesional de la información, 26(4), 672-683. https://doi.org/10.3145/epi.2017.jul.11
Oliva, C. (2014). El periodismo digital y sus retos en la sociedad global y del conocimiento. Aposta. Revista de Ciencias Sociales. (61), 1-30. https://www.redalyc.org/articulo.oa?id=495950257004
Parodi, G. (2005). Discurso especializado y lingüística de corpus: hacia el desarrollo de una competencia psicolingüística. Boletín de Lingüística, 23, 61-88. https://www.redalyc.org/articulo.oa?id=34702304
Parodi, G. (2011). La Teoría de la Comunicabilidad: notas para una concepción integral de la comprensión de textos escritos. Revista Signos, 44(76), 145-167.
Parodi, G. (2014). Comprensión de textos escritos. Eudeba.
Parodi, G., Julio, C. (2017): No solo existen palabras en los textos escritos: algunas teorías y modelos de comprensión de textos multimodales o multisemióticos, Investigaciones sobre Lectura, (8), 27-48.
Parodi, G., Moreno, T., Julio, C. (2020a). Comprensión de textos escritos: reconceptualizaciones en torno a las demandas del siglo XXI. Íkala, Revista de Lenguaje y Cultura, 25(3), 775-795.
Parodi, G., Moreno-de-León, T., Julio, C., Burdiles, G. (2020b). Comprensión de múltiples textos multimodales y objetivos de lectura: Un estudio con profesionales de economía. En G. Parodi, & C. Julio (Eds.). (2020). Comprensión y discurso: Del movimiento ocular al procesamiento cognitivo. Ediciones Universitarias de Valparaíso. http://bit.ly/3Ul2IPE
Ramírez, D., Siles, I. (2020). Prácticas y dinámicas de creación de memes en Costa Rica. Virtualis, 11(21), 68-88.
Rost, A. (2009). Desde los hechos hasta la noticia. Revista de la Facultad, (15), 237-265.
Rowan (2015).VI. Memes. Inteligencia idiota, política rara y folclore digital. Capitán Swing Libros
Sadosky, M., Paivio, A. (2013). Imagery and Text. A dual coding theory of reading and writing. Routledge.
Siles, I. (2020). Democracia en digital: Facebook, comunicación y política en Costa Rica. Espacio Universitario de Estudios Avanzados
Sülflow, M., Schäfer, S., Winter, S. (2018). Selective attention in the news feed: An eye-tracking study on the perception and selection of political news posts on Facebook. New Media & Society. 21(1), 168-190. https://doi.org/10.1177/1461444818791520
Van Dijk, T., Kintsch, W. (1983). Strategies of Discourse Comprehension. Academic Press.
Vergara, A. (2021). Desinformación y multimodalidad: un acercamiento a la composición multimodal de textos desinformativos. En I. Siles González, L. Tristán Jiménez & C. Carazo Barrantes (Eds.). Verdad en extinción: miradas interdisciplinarias a la desinformación en Costa Rica. Centro de Investigación en Comunicación
Vergara, A., Siles, I., Castro, A., Chavarría, W. (2020b). La lectura de textos multimodales en el uso de redes sociales: Estudio exploratorio con el uso del registro de movimientos oculares. En G. Parodi & C. Julio (Eds.). Comprensión y discurso: Del movimiento ocular al procesamiento cognitivo. Ediciones Universitarias de Valparaíso.
Vraga, E., Bode, L., Troller, S. (2016) Beyond Self-Reports: Using Eye Tracking to Measure Topic and Style Differences in Attention to Social Media Content. Communication Methods and Measures, 10(2-3), 149-164
Wilson, F., Oliveira, C. (2022). Manifestação da linguagem humana em ‘Memes’: mecanismos linguístico-discursivos. Revista de Estudos de Português Língua Internacional, 2(1), 95-115.
Yus, F. (2019). Multimodality in Memes: A Cyberpragmatic Approach. Analyzing Digital Discourse. In P. Bou-Franch & P. Garcés-Conejos Blitvich (Eds.). Analyzing Digital Discourse: New Insights and Future Directions. https://doi.org/10.1007/978-3-319-92663-6